

NVIDIA, yapay zeka alanında tarihi bir adım atarak Nemotron-CC ismini verdiği devasa bir İngilizce AI eğitim veritabanını duyurdu. Yeni veritabanı, toplam 6.3 trilyon token içeriyor ve bunun 1.9 trilyonu sentetik bilgilerden oluşuyor. NVIDIA, bu yeni veritabanının, büyük lisan modrinin (LLM) eğitimi için bugüne kadar geliştirilen en kapsamlı kaynaklardan biri olduğunu belirtti. Şirket, bilhassa akademik ve ticari alanlarda bu yeniliğin büyük bir fark yaratacağını söz etti. İşte detaylar…
NVIDIA 6.3 trilyon tokenli yapay zeka eğitim veritabanı Nemotron-CC modelini tanıttı
Nemotron-CC veritabanının geliştirilme sürecinde, Common Crawl platformundan alınan büyük ölçüde data kullanıldığı aktarıldı. Bu bilgiler, sıkı bir data sürece ve filtreleme sürecinden geçirilerek yüksek kaliteli bir alt küme olan Nemotron-CC-HQ oluşturulmuş. NVIDIA, bu veritabanının “büyük lisan modri için ülkü bir eğitim materyali” olduğunu söylüyor.
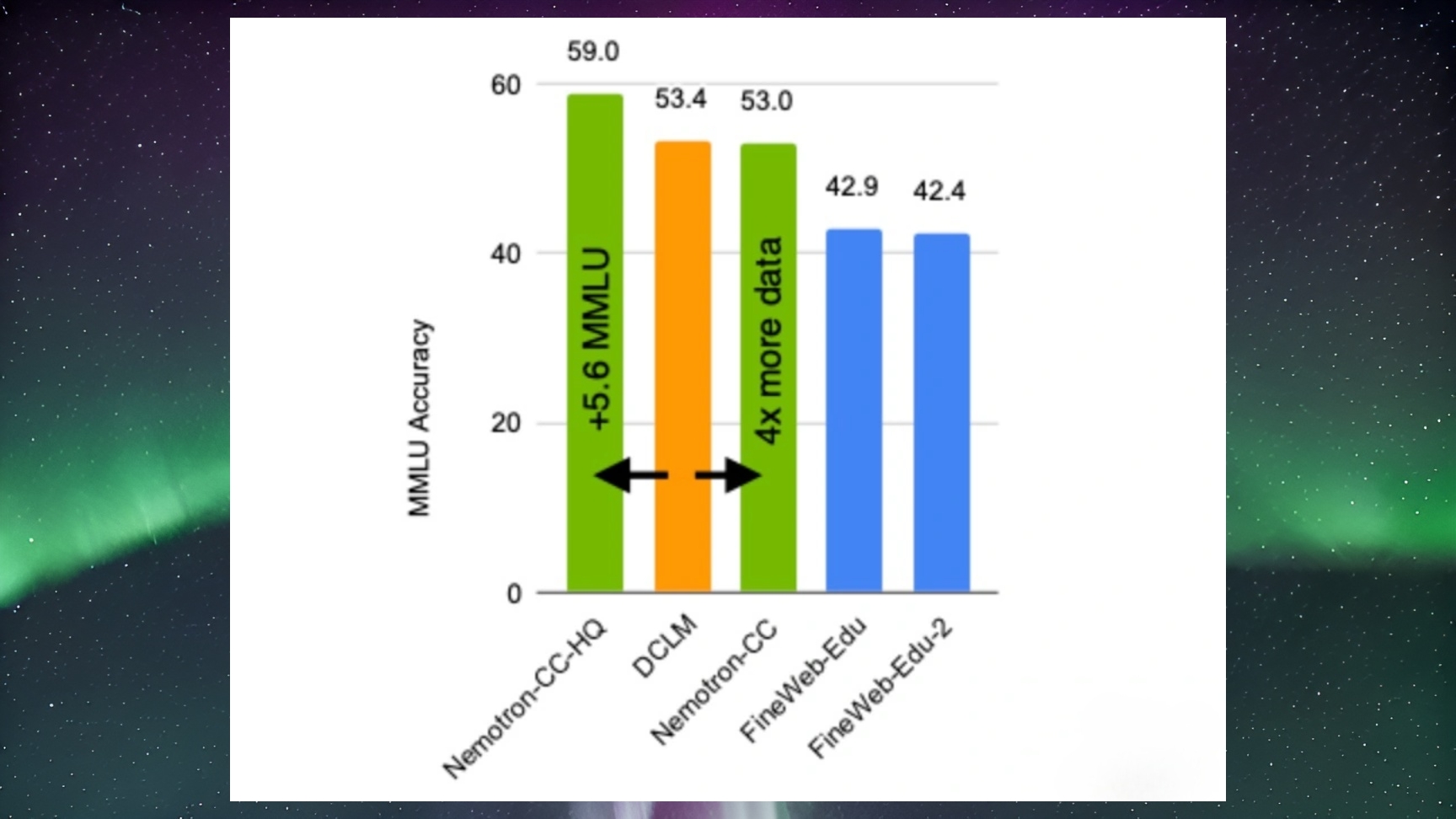
Aslında bu yeniliğin, mevcut eğitim veritabanlarının ölçek ve kalite bakımından karşılaştığı kısıtlamalara tahlil sunması bekleniyor. Bilhassa Deep Common Crawl Language Model (DCLM) üzere başkan açık kaynak veritabanlarına kıyasla daha üstün bir performans sunacak. NVIDIA, Nemotron-CC ile eğitilen modrin çeşitli testlerde dikkate bedel iyileştirmeler sağladığını açıkladı. Örneğin:
- MMLU (Massive Multitask Language Understanding) testlerinde mevcut sistemlere kıyasla 5.6 puan artış elde edildi.
- 80 milyar parametreli modr, MMLU testlerinde 5 puan, ARC-Challenge testlerinde ise 3.1 puan düzgünleşme gösterdi.
- Nemotron-CC’nin, öteki yüksek kaliteli veritabanları ile karşılaştırıldığında 10 farklı vazifede ortalama 0.5 puanlık bir performans artışı sağladığı belirtildi.

Nvidia CEO’sundan RTX 5090’ın fiyatını eleştirenlere karşılık: “Kalitenin bedeli var!”
Nvidia CEO’su Jensen Huang, uzun vakittir tartışma konusu olan RTX 5090’ın fiyatıyla ilgili konuştu. İşte ayrıntılar…
Ortaya çıkan sonuçlara bakılırsa, Nemotron-CC’nin büyük lisan modrinin eğitimi ve yetenekleri üzerinde nasıl bir tesir yaratabileceğini açıkça görüyoruz. Bununla birlikte NVIDIA, Nemotron-CC’nin geliştirilmesinde model sınıflandırıcılar, sentetik data yine söz etme (rephrasing) üzere tekniklerden yararlandığını duyurdu. Bu teknikler, veritabanındaki data çeşitliliğini ve kalitesini artırmak için kullanılmış. Ayrıyeten, klasik data filtreleme formüllerindeki sıkı kuralların hafifletilmesiyle yüksek kaliteli tokenların sayısı da artırılmış.
NVIDIA, Nemotron-CC’yi Common Crawl platformu üzerinden erişime açtı ve bu veritabanının dökümantasyonunu yakında şirketin GitHub sayfasında yayınlayacağını duyurdu. Bu sayede hem akademisyenler hem de ticari kullanıcılar, bu veritabanını kolaylıkla kullanabilecek. Yeni veritabanına buradan erişebilirsiniz.
Peki sizce bu yeniliğin yapay zeka teknolojilerinin geleceği üzerindeki tesirleri ne olur? Görüşlerinizi aşağıdaki yorumlar kısmında paylaşabilirsiniz…












